Claude ali ChatGPT? Napačno vprašanje

V zadnjih tednih se veliko razprav vrti okoli Clauda. Tudi sam ga redno uporabljam, vključno s plačljivo pro različico, zlasti pri zahtevnih poslovnih vprašanjih. Toda zadnja izkušnja me je opozorila na past, v katero hitro pademo vsi, ki spremljamo to področje: občutek, da imamo aktualno in objektivno sliko.
Nimamo je vedno.
Trg se premika zelo hitro. Vrhunski modeli se menjajo v kratkih ciklih, pogosto v nekaj tednih ali mesecih. Vsaka primerjava je zato uporabna samo z datumom, modelno različico in metodologijo ob sebi. Spodnja ocena velja za junij 2026.
Kaj kažejo benchmarki?
Na neodvisnem agregatnem indeksu sta modela zelo blizu. Artificial Analysis Intelligence Index postavlja Claude Opus 4.8 na 61,4 in GPT-5.5 na 60,2. Razlika 1,2 točke pomeni, da skupna razvrstitev sama po sebi pove malo. Pomembnejše so razlike po posameznih nalogah, še pomembnejše pa je, kako so bile te naloge merjene.
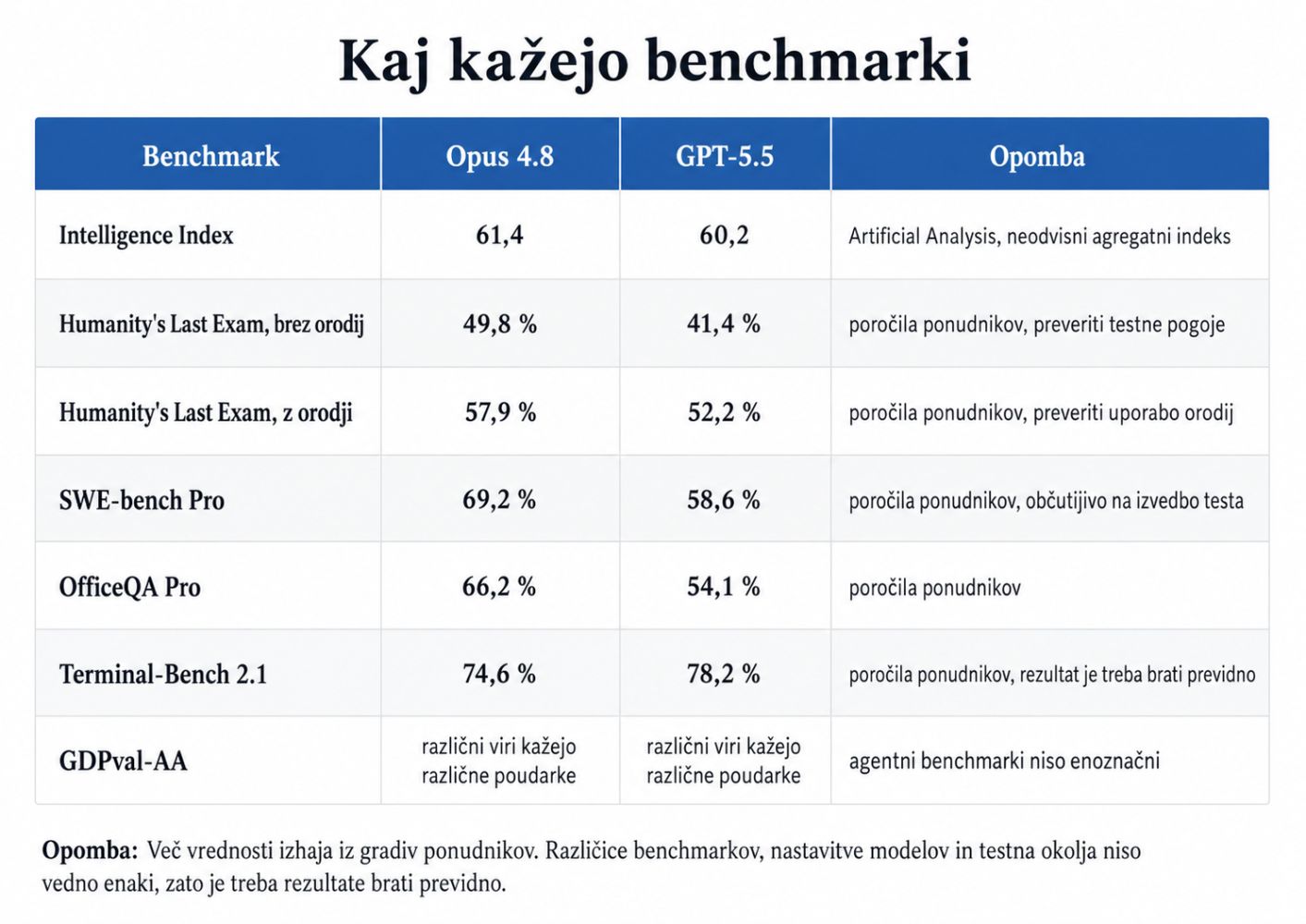
Vrednosti, ki izhajajo iz gradiv ponudnikov, je treba brati posebej previdno. Različice benchmarkov, nastavitve modelov, dovoljena orodja, agentni okvirji in testna okolja niso vedno enaki. Zato takšne številke niso dokončna razvrstitev, ampak signal.
Vzorec je uporaben, ni pa dokončen. Trenutni podatki nakazujejo prednost Claude Opus 4.8 pri delu z zahtevnimi dokumenti, pri nekaterih nalogah sklepanja, pri pravnih in pisarniških opravilih ter pri nalogah, kjer je pomembno opozarjanje na negotovost. GPT-5.5 je zelo konkurenčen, zlasti pri terminalskih nalogah, učinkovitosti korakov in nekaterih agentnih potekih dela.
Pri programiranju je slika manj enoznačna. SWE-bench Pro daje prednost Claudu, medtem ko je en neodvisni programerski test, DeepSWE iz maja 2026, pokazal prednost GPT-5.5. Ta test je sicer meril Claude Opus 4.7, ne 4.8, zato ga ne moremo neposredno uporabiti kot dokaz proti novejšemu Claudu. Je pa dober opomnik, da lahko druga metodologija spremeni vrstni red modelov.
Benchmarki torej kažejo smer. Ne dajejo pa dokončne resnice.
Konkreten primer iz prakse: pravo
Za poslovne uporabnike je včasih bolj uporaben specifičen benchmark kot splošni indeks. Harvey poroča, da je Claude Opus 4.8 dosegel najvišji zabeleženi rezultat na njihovem Legal Agent Benchmarku in postal prvi model, ki je presegel 10 % na njihovem najstrožjem all-pass standardu.
Če delate s pravnimi besedili v podobnih nalogah, kot jih meri Harveyjev benchmark, je to konkreten signal. Vendar tudi tu velja previdnost: gre za rezultat v specifičnem okolju, s specifičnim načinom ocenjevanja in v poročilu ponudnika oziroma partnerskega ekosistema. To ni dokaz, da je en model vedno najboljši za vsa pravna opravila.
Kontekstno okno: nazivna številka ni dovolj
Oba modela danes ponujata zelo velika kontekstna okna, do približno enega milijona tokenov. To je ogromno. Približno pomeni več sto tisoč besed v enem vhodu.
Toda nazivna dolžina konteksta ni isto kot kakovost razumevanja celotnega konteksta. Model lahko tehnično sprejme zelo dolg dokument, pa kljub temu izgublja podrobnosti, slabše povezuje oddaljene dele besedila ali spregleda pomembne izjeme.
Pri delu z gostimi dokumenti, dolgimi pogodbami, razpisno dokumentacijo ali analizo več virov hkrati je zato ključno testirati na realnih primerih. Ne samo vprašati, koliko tokenov model sprejme, ampak preveriti, ali zna v dolgem dokumentu najti izjemo, povezati več členov, opaziti protislovje in jasno povedati, kje ni prepričan.
Po dostopnih primerjavah ima Claude Opus 4.8 pri zelo dolgih in gostih dokumentih trenutno močne signale. GPT-5.5 je pri dolgokontekstnem delu prav tako napredoval. Zato razlike ni smiselno opisovati samo kot specifikacijo na papirju, ampak kot praktično vprašanje: kateri model pri vaših dokumentih naredi manj napak?
Cena
Po dostopnih podatkih imata modela primerljivo vhodno ceno, Claude pa je pri izhodnih tokenih nekoliko cenejši. Toda primerjava cen pri velikih modelih ni tako preprosta.
Cena na milijon tokenov ni vedno enaka ceni za isto poslovno nalogo. Pomembni so tudi dolžina odgovorov, cache pricing, batch način, število agentnih korakov, uporaba orodij in tokenizer. Pri nekaterih modelih lahko isti dokument pomeni drugačno število tokenov.
Zato je najbolj smiselno strošek računati na dejanski primer uporabe. Na primer: ena pogodba, deset vprašanj, dve iteraciji popravkov, en končni povzetek. Šele tak izračun pove, kateri model je za vaše delo res cenejši.
Ceniki se pogosto spreminjajo, zato jih je treba pred odločitvijo preveriti pri ponudniku in preračunati na svoj dejanski obseg uporabe.
Kako to uporabiti v podjetju?
- Glavno orodje izberite glede na naloge, ki jih opravljate najpogosteje. Če imate veliko terminalskega, integracijskega ali agentnega dela, je GPT-5.5 zelo močan kandidat. Če imate veliko zahtevnih analiz, dolgih dokumentov, pogodb, pravnih besedil ali primerjave več virov, ima Claude Opus 4.8 trenutno zelo močne signale.
- Drugi model dodajte zavestno, ne po navadi. Imeti oba modela se lahko splača, vendar ne zato, ker je to moderno. Smiselno je, če ima vsak jasno vlogo. Na primer en model za dolge analize in drugi za agentne poteke dela ali integracije.
- Pred uvajanjem uredite interno politiko. Brez pravil nastane t.i. shadow AI: skrita uporaba orodij brez nadzora. To je lahko pravno, varnostno in organizacijsko problematično. Podjetje mora jasno urediti, kateri podatki se lahko vnašajo, katera orodja so dovoljena, kdo ima dostop, kako se ravna z zaupnimi dokumenti, kaj se beleži in kje se podatki obdelujejo.
- Ne zaupajte benchmarkom slepo. Testirajte na svojih primerih. Vzemite en resničen dokument, eno poslovno vprašanje in en tipičen proces. Merite kakovost odgovora, število napak, uporabnost, čas popravkov in samozavest modela pri negotovih delih. To je za vaše podjetje pomembnejše od splošne lestvice.
- Zaposlene učite razlikovati med nalogami, ne med imeni modelov. Večina zaposlenih ne potrebuje dolgega seznama modelov. Potrebujejo praktično razumevanje, kdaj uporabiti AI, kdaj uporabiti kateri tip orodja in kdaj AI sploh ni primerna rešitev.
Zaključek
Večina podjetij AI še vedno uporablja površinsko: napiši, prevedi, povzemi. Pri takšni rabi razlike med vrhunskimi modeli pogosto niso odločilne. Vprašanje “kateri je boljši” je v takih primerih manj pomembno od vprašanja, ali zaposleni sploh znajo dobro zastaviti nalogo in preveriti rezultat.
Razlike se pokažejo pri težjih nalogah: ko je treba razumeti kontekst, primerjati vire, preveriti argumente, analizirati dolge dokumente ali zgraditi kakovostno odločitev.
Trenutni benchmarki nakazujejo, da je Claude Opus 4.8 med najmočnejšimi modeli pri zahtevnih dokumentih, pravnih in pisarniških nalogah ter nekaterih oblikah sklepanja. GPT-5.5 ostaja zelo močan pri terminalskem delu, agentnih potekih in učinkovitosti izvedbe. Pri programiranju in agentnih nalogah slika ni povsem enoznačna, ker različni testi merijo različne stvari.
Zato trajna prednost ni izbira “pravega” modela enkrat za vselej. Trajna prednost je sposobnost, da za konkreten problem izberete pravo orodje, ga preverite na svojih primerih in znate razložiti, zakaj ste ga izbrali.

